4 Manipuler et traîter les données façon bases de données
“Actually, I see it as part of my job to inflict R on people who are perfectly happy to have never heard of it. Happiness doesn’t equal proficient and efficient. In some cases the proficiency of a person serves a greater good than their momentary happiness.” — P. Burns
4.1 Vue d’ensemble
Dans ce module, la notion de « données ordonnées » (tidy data) est introduite. Il s’agit d’une vision formelle d’un tableau de données dans lequel les colonnes sont des variables, les lignes des individus (au sens statistique) et les cellules les valeurs des données. C’est une approche communément utilisée, par exemple dans les bases de données, qui est parfaite pour la manipulation et le traîtement efficaces des données.

On partira ici sur l’hypothèse de travail forte que nous disposons déjà de données ordonnées (c’est à peu près le cas des données SISE ou APOGEE). Ce n’est malheureusement pas toujours le cas — il existe alors des outils pour y parvenir, notamment ceux fournis par le package tidyr.
Le pendant de ggplot2 pour les données est le package dplyr, qui s’appuie si
l’on veut sur une « grammaire des données ». Cette grammaire est très proche
dans l’esprit et dans le vocabulaire du langage SQL utilisé sur la plupart des
bases de données relationnelles. Elle contient un certain nombre de « verbes »
(des fonctions R) qui permettent de combiner des tableaux, manipuler des
variables et des individus, ainsi que de synthétiser des données. C’est tout
l’objet de ce module. Nous commençons donc par charger le package dplyr :
library("dplyr")
La fiche de synthèse pour la manipulation des données avec dplyr est parfaite pour ne pas avoir à mémoriser tous ces verbes et les éléments principaux de leur syntaxe. La fiche est disponible en cliquant sur la vignette ci-dessous (en anglais) :

4.2 Importation de toutes les données
Les données étudiants sont éparpillées sur un certain nombre de fichiers :
- 1 fichier APOGEE UM pour les inscrits 2018–2019 (
2018 2019 Apogée anonymisée.xlsx) - 7 fichiers SISE pour les inscrits 2018–2019 (
ins_culture_18_ano.csv,ins_enq_18_ano.csv,ins_ens_18_ano.csv,ins_inge_18_ano.csv,ins_mana_18_ano.csv,ins_priv_18_ano.csv,ins_univ_18_ano.csv)
Le plus simple est de tous les importer d’un coup, comme nous l’avons vu dans le module précédent. Pour cela, on peut exécuter le bloc suivant dans son intégralité :
apogee_18 <- readxl::read_excel("data/2018 2019 Apogée anonymisée.xlsx")
library("readr")
ins18_culture <- read_csv2("data/ins_culture_18_ano.csv", na = c("", "."), col_types =
cols(
ACAETA = col_character(),
COMPOS = col_character(),
CURPAR = col_character(),
CURSUS_LMD = col_character(),
CYCLE = col_double(),
DEGETU = col_character(),
DEPETA = col_character(),
DIPDER = col_character(),
DIPLOM = col_character(),
DISCIPLI = col_character(),
EFFECTIF = col_double(),
ETABLI = col_character(),
GROUPE = col_character(),
IDETU = col_double(),
NBACH = col_double(),
NET = col_double(),
NIVEAU = col_character(),
NUMED = col_character(),
NUMINS = col_character(),
PARIPA = col_character(),
REGIME = col_double(),
SECTDIS = col_character(),
SITUPRE = col_character(),
TYPREPA = col_character(),
TYP_DIPL = col_character(),
VOIE = col_double()
))
ins18_enq <- read_csv2("data/ins_enq_18_ano.csv", na = c("", "."), col_types =
cols(
ACAETA = col_character(),
COMPOS = col_character(),
CURPAR = col_character(),
CURSUS_LMD = col_character(),
CYCLE = col_double(),
DEGETU = col_character(),
DEPETA = col_character(),
DIPDER = col_character(),
DIPLOM = col_character(),
DISCIPLI = col_character(),
EFFECTIF = col_double(),
ETABLI = col_character(),
FLAG_MEEF = col_double(),
GROUPE = col_character(),
IDETU = col_double(),
NBACH = col_double(),
NET = col_double(),
NIVEAU = col_character(),
NUMED = col_character(),
NUMINS = col_character(),
PARIPA = col_character(),
REGIME = col_double(),
SECTDIS = col_character(),
SITUPRE = col_character(),
TYPREPA = col_character(),
TYP_DIPL = col_character(),
VOIE = col_double()
))
ins18_ens <- read_csv2("data/ins_ens_18_ano.csv", na = c("", "."), col_types =
cols(
ACAETA = col_character(),
COMPOS = col_character(),
CONV = col_character(),
CURPAR = col_character(),
CURSUS_LMD = col_character(),
CYCLE = col_double(),
DEGETU = col_character(),
DEPETA = col_character(),
DIPDER = col_character(),
DIPLOM = col_character(),
DISCIPLI = col_character(),
EFFECTIF = col_double(),
ETABLI = col_character(),
ETABLI_DIFFUSION = col_character(),
flag_meef = col_double(),
GROUPE = col_character(),
IDETU = col_double(),
NBACH = col_double(),
NET = col_double(),
NIVEAU = col_character(),
NUMED = col_character(),
NUMINS = col_character(),
PARIPA = col_character(),
REGIME = col_double(),
SECTDIS = col_character(),
SITUPRE = col_character(),
SPECIA = col_character(),
SPECIB = col_character(),
TYPREPA = col_character(),
TYP_DIPL = col_character(),
UNIV = col_character(),
VOIE = col_double()
))
ins18_inge <- read_csv2("data/ins_inge_18_ano.csv", na = c("", "."), col_types =
cols(
ACAETA = col_character(),
COMPOS = col_character(),
CURPAR = col_character(),
CURSUS_LMD = col_character(),
CYCLE = col_double(),
DEGETU = col_character(),
DEPETA = col_character(),
DIPDER = col_character(),
DIPLOM = col_character(),
DISCIPLI = col_character(),
EFFECTIF = col_double(),
ETABLI = col_character(),
flag_meef = col_double(),
GROUPE = col_character(),
IDETU = col_double(),
NBACH = col_double(),
NET = col_double(),
NIVEAU = col_character(),
NUMED = col_character(),
NUMINS = col_character(),
PARIPA = col_character(),
REGIME = col_double(),
SECTDIS = col_character(),
SITUPRE = col_character(),
SPECIA = col_character(),
SPECIB = col_character(),
TYPREPA = col_character(),
TYP_DIPL = col_character(),
VOIE = col_double()
))
ins18_mana <- read_csv2("data/ins_mana_18_ano.csv", na = c("", "."), col_types =
cols(
ACAETA = col_character(),
COMPOS = col_character(),
CURSUS_LMD = col_character(),
CYCLE = col_double(),
DEGETU = col_character(),
DEPETA = col_character(),
DIPDER = col_character(),
DIPLOM = col_character(),
DISCIPLI = col_character(),
EFFECTIF = col_double(),
ETABLI = col_character(),
GROUPE = col_character(),
IDETU = col_double(),
NBACH = col_double(),
NET = col_double(),
niveau = col_character(),
NUMED = col_character(),
NUMINS = col_character(),
PARIPA = col_character(),
REGIME = col_double(),
SECTDIS = col_character(),
SITUPRE = col_character(),
TYPREPA = col_character(),
TYP_DIPL = col_character(),
VOIE = col_double()
))
ins18_priv <- read_csv2("data/ins_priv_18_ano.csv", na = c("", "."), col_types =
cols(
ACAETA = col_character(),
COMPOS = col_character(),
CONV = col_character(),
CURPAR = col_character(),
CURSUS_LMD = col_character(),
CYCLE = col_double(),
DEGETU = col_character(),
DEPETA = col_character(),
DIPDER = col_character(),
DIPLOM = col_character(),
DISCIPLI = col_character(),
EFFECTIF = col_double(),
ETABLI = col_character(),
ETABLI_DIFFUSION = col_character(),
flag_meef = col_double(),
GROUPE = col_character(),
IDETU = col_double(),
NBACH = col_double(),
NET = col_double(),
NIVEAU = col_character(),
NUMED = col_character(),
NUMINS = col_character(),
PARIPA = col_character(),
REGIME = col_double(),
SECTDIS = col_character(),
SITUPRE = col_character(),
SPECIA = col_character(),
SPECIB = col_character(),
TYPREPA = col_character(),
TYP_DIPL = col_character(),
VOIE = col_double()
))
ins18_univ <- read_csv2("data/ins_univ_18_ano.csv", na = c("", "."), col_types =
cols(
ACAETA = col_character(),
COMPOS = col_character(),
CONV = col_character(),
CURPAR = col_character(),
CURSUS_LMD = col_character(),
CYCLE = col_double(),
DEGETU = col_character(),
DEPETA = col_character(),
DIPDER = col_character(),
DIPLOM = col_character(),
DISCIPLI = col_character(),
EFFECTIF = col_double(),
ETABLI = col_character(),
ETABLI_DIFFUSION = col_character(),
flag_meef = col_double(),
GROUPE = col_character(),
IDETU = col_double(),
NBACH = col_double(),
NET = col_double(),
NIVEAU = col_character(),
NUMED = col_character(),
NUMINS = col_character(),
PARIPA = col_character(),
REGIME = col_double(),
SECTDIS = col_character(),
SITUPRE = col_character(),
SPECIA = col_character(),
SPECIB = col_character(),
TYPREPA = col_character(),
TYP_DIPL = col_character(),
UNIV = col_character(),
VOIE = col_double()
))Par commodité, on changera tous les noms de variable en minuscules — et au
passage, on apprend notre première fonction dplyr, rename_with (pour
renommer avec des noms spécifiés manuellement, on utilisera simplement rename)
:
apogee_18 <- rename_with(apogee_18, tolower)
apogee_18# A tibble: 57,699 x 41
decede annee_univ idetu civilite date_naiss code departement_pays
<chr> <dbl> <dbl> <chr> <dttm> <chr> <chr>
1 non 2018 1035789 Mme 2000-10-05 00:00:00 84 VAUCLUSE
2 non 2018 2211839 M 1997-06-16 00:00:00 6 ALPES MARITIMES
3 non 2018 2211840 M 2000-04-13 00:00:00 84 VAUCLUSE
4 non 2018 921768 Mme 1993-10-08 00:00:00 205 LIBAN
5 non 2018 921685 Mme 1994-10-02 00:00:00 352 ALGERIE
6 non 2018 2211841 M 1992-03-27 00:00:00 127 ITALIE
7 non 2018 921909 Mme 1995-10-06 00:00:00 205 LIBAN
8 non 2018 921827 M 1995-05-05 00:00:00 134 ESPAGNE
9 non 2018 2211842 Mme 1990-01-08 00:00:00 331 BURKINA FASO
10 non 2018 921775 M 1988-05-01 00:00:00 352 ALGERIE
# … with 57,689 more rows, and 34 more variables: code_nationalite <dbl>,
# libelle_nationalite <chr>, bac <chr>, bac_regroup <chr>, annee_bac <dbl>,
# departement_bac <chr>, regime <chr>, bourse <chr>, echelon_bourse <chr>,
# pcs_parent <chr>, pcs_parent_autre <chr>, lic_tpd <chr>, composante <chr>,
# domaine_disciplinaire <chr>, mention <chr>, code_sise_diplome <dbl>,
# diplome <chr>, code_diplome <chr>, intitule1_sise <chr>, code_etape <chr>,
# lib_etape <chr>, intitule2_sise <chr>, version_de_diplome <chr>,
# inscription_premiere <chr>, nature_diplome <chr>, temoin_dip <chr>,
# cp_annuel <dbl>, pays_annuel <chr>, cp_fixe <dbl>, pays_fixe <chr>,
# date_inscription_iae <dttm>, prem_insc_univ_fr <dbl>,
# date_premiere_ins_ens_sup <dbl>, prem_insc_etab <dbl>ins18_culture <- rename_with(ins18_culture, tolower)
ins18_enq <- rename_with(ins18_enq, tolower)
ins18_ens <- rename_with(ins18_ens, tolower)
ins18_inge <- rename_with(ins18_inge, tolower)
ins18_mana <- rename_with(ins18_mana, tolower)
ins18_priv <- rename_with(ins18_priv, tolower)
ins18_univ <- rename_with(ins18_univ, tolower)4.3 Combiner des tableaux
Combiner plusieurs tableaux de données n’est pas si simple qu’il n’y parait. Il
faut tout d’abord s’accorder sur le sens de combinaison (« vertical » ou «
horizontal »), puis sur la marche à suivre pour les colonnes et/ou individus qui
ne sont pas présents dans tous les tableaux. Fort heureusement, dplyr fournit
des outils très intuitifs pour tout cela.
4.3.1 Combiner plusieurs tableaux verticalement : bind_rows()
Pour combiner plusieurs tableaux verticalement, il existe la fonction
bind_rows — en pratique, elle consiste à rajouter des lignes supplémentaires.
Si des colonnes existent dans certains tableaux mais pas dans tous, elles sont
remplies de NAs :
dim(ins18_culture)[1] 81063 26ins18 <- bind_rows(ins18_culture, ins18_enq, ins18_ens, ins18_inge, ins18_mana, ins18_priv, ins18_univ)
dim(ins18)[1] 2417825 32Il existe la même opération par colonnes — l’équivalent de simplement rajouter
des colonnes supplémentaires — via la fonction bind_cols qui fait donc une
combinaison horizontale (à noter que tous les tableaux doivent avoir le même
nombre de lignes).
4.3.2 Jointure logique : left_join()
Lorsque l’on combine plusieurs tableaux horizontalement (ajout de colonnes), il
peut être préférable de s’assurer au préalable que les lignes des tableaux
correspondent. C’est l’approche de la jointure (ou appariement) logique, qui
s’appuye sur une ou plusieurs colonne pour identifier les lignes (les individus
statistiques) correspondantes entre les deux tableaux. La jointure la plus
courante (et peut-être la plus intuitive) est la jointure avec le tableau de
gauche en référence (left_join()) : on rajoute les informations (nouvelles
colonnes) des individus du tableau de droite qui correspondent à ceux du tableau
de gauche. Il existe également la jointure avec le tableau de droite en
référence (right_join()), la jointure « interne » qui ne conserve que les
individus présents dans les deux tableaux (inner_join()) et la jointure
complète qui conserve tous les individus des deux tableaux (full_join()). Un
petit dessin vaut parfois mieux qu’un long discours, voici la jointure illustrée
:
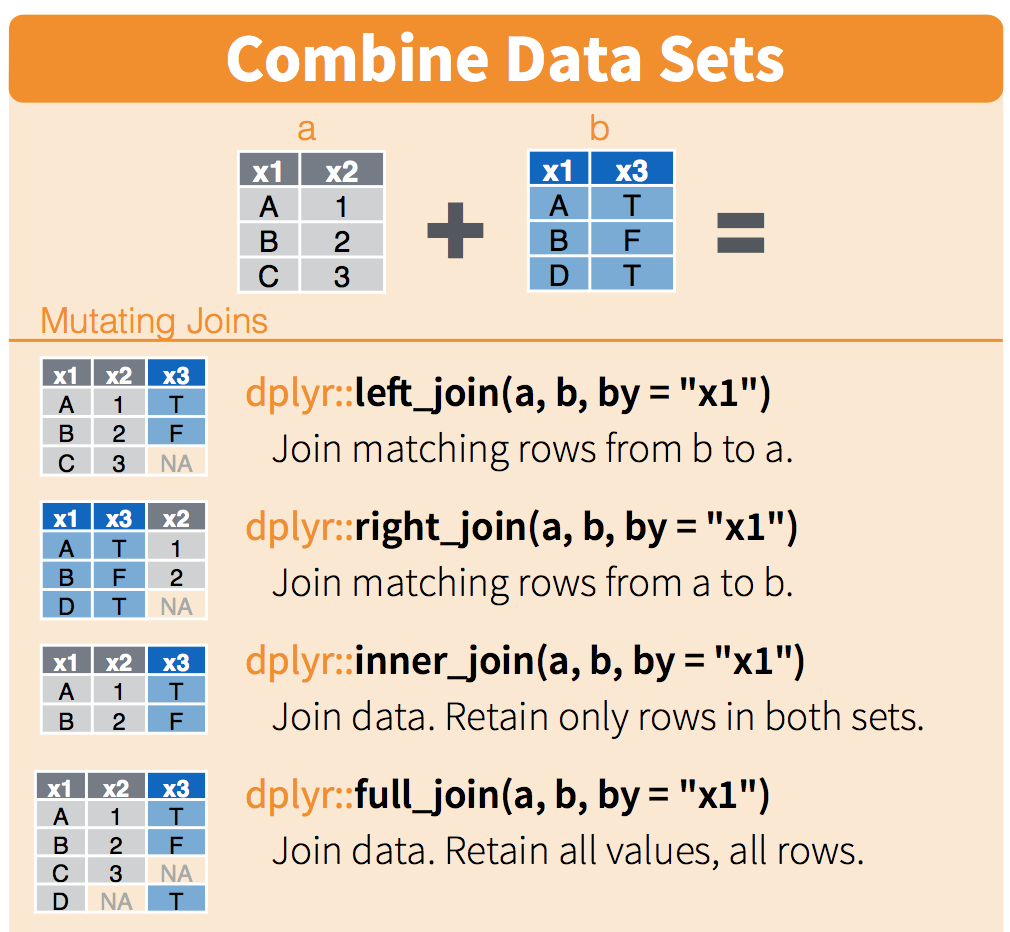
Dans le cadre de ce module, on ne présentera que la jointure par la gauche avec
la fonction left_join() qui, en plus des deux tableaux, nécessite seulement de
spécifier la (ou les) colonne(s) utilisée(s) pour la correspondance :
dim(apogee_18)[1] 57699 41dim(ins18)[1] 2417825 32um18 <- left_join(apogee_18, ins18, by = "idetu")
dim(um18) # Adds duplicated in both tables[1] 70800 72Noter le temps d’exécution très court pour combiner un tableau de près de 2,5 millions de ligne à notre tableau de gauche ! On peut remarquer que le tableau final contient plus de variables (c’était attendu), mais également plus d’individus que le tableau de gauche initial : C’est parce qu’il y a des étudiants qui apparaissent plusieurs fois (inscriptions multiples) dans le tableau de droite — ils sont répliqués autant de fois que nécessaire à gauche pour y ajouter toutes les lignes de droite.
4.4 Manipuler des variables et des individus
4.4.1 Filtrer selon un critère : filter()
Le prochain verbe est filter(), qui, comme son nom l’indique, permet de
filtrer des lignes selon un critère défini. Les critères s’appuient sur les
opérateurs de comparaison :
==: égalité (attention, c’est bien un double signe égal !)<,<=,>=,>: inférieur, inférieur ou égal, supérieur ou égal, supérieur!: différent%in%: est-ce que la (ou les valeurs) apparaissent dans une série de valeurs ?
toto <- 2
toto == 2[1] TRUEtoto <= 2[1] TRUEtoto != 2[1] FALSE!(toto == 2)[1] FALSEtoto %in% 5:10[1] FALSELa même chose avec un vecteur de valeurs :
toto <- 1:10
toto > 1 & toto <= 3 [1] FALSE TRUE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSEOn peut par exemple filtrer uniquement les étudiants nés dans l’Hérault :
filter(um18, departement_pays == "HERAULT")# A tibble: 15,156 x 72
decede annee_univ idetu civilite date_naiss code departement_pays
<chr> <dbl> <dbl> <chr> <dttm> <chr> <chr>
1 non 2018 2211884 Mme 1999-06-29 00:00:00 34 HERAULT
2 non 2018 2211886 M 1999-07-28 00:00:00 34 HERAULT
3 non 2018 2211887 M 2001-01-18 00:00:00 34 HERAULT
4 non 2018 2211887 M 2001-01-18 00:00:00 34 HERAULT
5 non 2018 2211888 Mme 1999-12-09 00:00:00 34 HERAULT
6 non 2018 904983 M 2000-06-15 00:00:00 34 HERAULT
7 non 2018 2211896 Mme 2000-09-16 00:00:00 34 HERAULT
8 non 2018 2211897 Mme 2000-01-01 00:00:00 34 HERAULT
9 non 2018 2211900 Mme 1999-11-28 00:00:00 34 HERAULT
10 non 2018 905213 Mme 1999-07-20 00:00:00 34 HERAULT
# … with 15,146 more rows, and 65 more variables: code_nationalite <dbl>,
# libelle_nationalite <chr>, bac <chr>, bac_regroup <chr>, annee_bac <dbl>,
# departement_bac <chr>, regime.x <chr>, bourse <chr>, echelon_bourse <chr>,
# pcs_parent <chr>, pcs_parent_autre <chr>, lic_tpd <chr>, composante <chr>,
# domaine_disciplinaire <chr>, mention <chr>, code_sise_diplome <dbl>,
# diplome <chr>, code_diplome <chr>, intitule1_sise <chr>, code_etape <chr>,
# lib_etape <chr>, intitule2_sise <chr>, version_de_diplome <chr>,
# inscription_premiere <chr>, nature_diplome <chr>, temoin_dip <chr>,
# cp_annuel <dbl>, pays_annuel <chr>, cp_fixe <dbl>, pays_fixe <chr>,
# date_inscription_iae <dttm>, prem_insc_univ_fr <dbl>,
# date_premiere_ins_ens_sup <dbl>, prem_insc_etab <dbl>, numins <chr>,
# compos <chr>, regime.y <dbl>, situpre <chr>, paripa <chr>, diplom <chr>,
# typrepa <chr>, dipder <chr>, niveau <chr>, etabli <chr>, acaeta <chr>,
# depeta <chr>, typ_dipl <chr>, sectdis <chr>, discipli <chr>, cycle <dbl>,
# degetu <chr>, curpar <chr>, nbach <dbl>, net <dbl>, effectif <dbl>,
# groupe <chr>, cursus_lmd <chr>, voie <dbl>, numed <chr>, flag_meef <dbl>,
# conv <chr>, specia <chr>, specib <chr>, etabli_diffusion <chr>, univ <chr>Le critère de filtre peut évidemment être plus complexe, et même multiple. Pour
combiner plusieurs critères, on utilise les opérateurs logiques & (ET logique)
et | (OU logique). Par exemple, pour filtrer les étudiants de genre masculin
nés après l’an 2000 :
filter(um18, (civilite == "M") & (date_naiss >= as.POSIXct("2000-01-01")))# A tibble: 3,443 x 72
decede annee_univ idetu civilite date_naiss code departement_pays
<chr> <dbl> <dbl> <chr> <dttm> <chr> <chr>
1 non 2018 2211840 M 2000-04-13 00:00:00 84 VAUCLUSE
2 non 2018 2211878 M 2000-04-10 00:00:00 4 ALPES DE HAUTE …
3 non 2018 2211879 M 2000-12-20 00:00:00 11 AUDE
4 non 2018 2211885 M 2000-03-16 00:00:00 58 NIEVRE
5 non 2018 2211887 M 2001-01-18 00:00:00 34 HERAULT
6 non 2018 2211887 M 2001-01-18 00:00:00 34 HERAULT
7 non 2018 2211891 M 2000-03-11 00:00:00 30 GARD
8 non 2018 2211891 M 2000-03-11 00:00:00 30 GARD
9 non 2018 2211892 M 2000-10-20 00:00:00 30 GARD
10 non 2018 904983 M 2000-06-15 00:00:00 34 HERAULT
# … with 3,433 more rows, and 65 more variables: code_nationalite <dbl>,
# libelle_nationalite <chr>, bac <chr>, bac_regroup <chr>, annee_bac <dbl>,
# departement_bac <chr>, regime.x <chr>, bourse <chr>, echelon_bourse <chr>,
# pcs_parent <chr>, pcs_parent_autre <chr>, lic_tpd <chr>, composante <chr>,
# domaine_disciplinaire <chr>, mention <chr>, code_sise_diplome <dbl>,
# diplome <chr>, code_diplome <chr>, intitule1_sise <chr>, code_etape <chr>,
# lib_etape <chr>, intitule2_sise <chr>, version_de_diplome <chr>,
# inscription_premiere <chr>, nature_diplome <chr>, temoin_dip <chr>,
# cp_annuel <dbl>, pays_annuel <chr>, cp_fixe <dbl>, pays_fixe <chr>,
# date_inscription_iae <dttm>, prem_insc_univ_fr <dbl>,
# date_premiere_ins_ens_sup <dbl>, prem_insc_etab <dbl>, numins <chr>,
# compos <chr>, regime.y <dbl>, situpre <chr>, paripa <chr>, diplom <chr>,
# typrepa <chr>, dipder <chr>, niveau <chr>, etabli <chr>, acaeta <chr>,
# depeta <chr>, typ_dipl <chr>, sectdis <chr>, discipli <chr>, cycle <dbl>,
# degetu <chr>, curpar <chr>, nbach <dbl>, net <dbl>, effectif <dbl>,
# groupe <chr>, cursus_lmd <chr>, voie <dbl>, numed <chr>, flag_meef <dbl>,
# conv <chr>, specia <chr>, specib <chr>, etabli_diffusion <chr>, univ <chr>Pour terminer, c’est une bonne manière de filtrer les lignes avec des valeurs
manquantes, en utilisant la forme !is.na() (« n’est pas une valeur manquante
») :
toto <- c(1:3, NA, 5:7, NA, 9)
is.na(toto)[1] FALSE FALSE FALSE TRUE FALSE FALSE FALSE TRUE FALSE!is.na(toto)[1] TRUE TRUE TRUE FALSE TRUE TRUE TRUE FALSE TRUEfilter(um18, !is.na(domaine_disciplinaire))# A tibble: 36,703 x 72
decede annee_univ idetu civilite date_naiss code departement_pays
<chr> <dbl> <dbl> <chr> <dttm> <chr> <chr>
1 non 2018 1035789 Mme 2000-10-05 00:00:00 84 VAUCLUSE
2 non 2018 2211840 M 2000-04-13 00:00:00 84 VAUCLUSE
3 non 2018 2211878 M 2000-04-10 00:00:00 4 ALPES DE HAUTE …
4 non 2018 2211879 M 2000-12-20 00:00:00 11 AUDE
5 non 2018 2211880 Mme 2000-12-04 00:00:00 351 TUNISIE
6 non 2018 2211881 Mme 2000-02-06 00:00:00 66 PYRENEES ORIENT…
7 non 2018 906628 M 1999-06-22 00:00:00 30 GARD
8 non 2018 905177 Mme 1999-06-27 00:00:00 976 MAYOTTE
9 non 2018 906223 Mme 1996-06-07 00:00:00 337 NIGER
10 non 2018 2211883 Mme 2000-06-09 00:00:00 11 AUDE
# … with 36,693 more rows, and 65 more variables: code_nationalite <dbl>,
# libelle_nationalite <chr>, bac <chr>, bac_regroup <chr>, annee_bac <dbl>,
# departement_bac <chr>, regime.x <chr>, bourse <chr>, echelon_bourse <chr>,
# pcs_parent <chr>, pcs_parent_autre <chr>, lic_tpd <chr>, composante <chr>,
# domaine_disciplinaire <chr>, mention <chr>, code_sise_diplome <dbl>,
# diplome <chr>, code_diplome <chr>, intitule1_sise <chr>, code_etape <chr>,
# lib_etape <chr>, intitule2_sise <chr>, version_de_diplome <chr>,
# inscription_premiere <chr>, nature_diplome <chr>, temoin_dip <chr>,
# cp_annuel <dbl>, pays_annuel <chr>, cp_fixe <dbl>, pays_fixe <chr>,
# date_inscription_iae <dttm>, prem_insc_univ_fr <dbl>,
# date_premiere_ins_ens_sup <dbl>, prem_insc_etab <dbl>, numins <chr>,
# compos <chr>, regime.y <dbl>, situpre <chr>, paripa <chr>, diplom <chr>,
# typrepa <chr>, dipder <chr>, niveau <chr>, etabli <chr>, acaeta <chr>,
# depeta <chr>, typ_dipl <chr>, sectdis <chr>, discipli <chr>, cycle <dbl>,
# degetu <chr>, curpar <chr>, nbach <dbl>, net <dbl>, effectif <dbl>,
# groupe <chr>, cursus_lmd <chr>, voie <dbl>, numed <chr>, flag_meef <dbl>,
# conv <chr>, specia <chr>, specib <chr>, etabli_diffusion <chr>, univ <chr>4.4.2 Trier les lignes par ordre croissant ou décroissant : arrange
Le verbe arrange() est tout ce qu’il y a de plus simple : il range les lignes
selon les valeurs d’une autre colonne, par défaut de manière croissante. Il est
toutefois très facile de le faire de manière décroissante :
arrange(um18, date_naiss)# A tibble: 70,800 x 72
decede annee_univ idetu civilite date_naiss code departement_pays
<chr> <dbl> <dbl> <chr> <dttm> <chr> <chr>
1 non 2018 897644 M 1936-08-25 00:00:00 25 DOUBS
2 non 2018 892414 Mme 1943-10-24 00:00:00 352 ALGERIE
3 non 2018 899283 M 1943-12-23 00:00:00 350 MAROC
4 non 2018 2224729 Mme 1945-03-14 00:00:00 69 RHONE
5 non 2018 899196 M 1945-04-29 00:00:00 352 ALGERIE
6 non 2018 895081 M 1945-07-28 00:00:00 971 GUADELOUPE
7 non 2018 2225524 Mme 1946-07-17 00:00:00 92 HAUTS DE SEINE
8 non 2018 897694 M 1946-09-21 00:00:00 352 ALGERIE
9 non 2018 901464 M 1947-11-18 00:00:00 30 GARD
10 non 2018 904911 Mme 1948-01-01 00:00:00 326 CÔTE D'IVOIRE
# … with 70,790 more rows, and 65 more variables: code_nationalite <dbl>,
# libelle_nationalite <chr>, bac <chr>, bac_regroup <chr>, annee_bac <dbl>,
# departement_bac <chr>, regime.x <chr>, bourse <chr>, echelon_bourse <chr>,
# pcs_parent <chr>, pcs_parent_autre <chr>, lic_tpd <chr>, composante <chr>,
# domaine_disciplinaire <chr>, mention <chr>, code_sise_diplome <dbl>,
# diplome <chr>, code_diplome <chr>, intitule1_sise <chr>, code_etape <chr>,
# lib_etape <chr>, intitule2_sise <chr>, version_de_diplome <chr>,
# inscription_premiere <chr>, nature_diplome <chr>, temoin_dip <chr>,
# cp_annuel <dbl>, pays_annuel <chr>, cp_fixe <dbl>, pays_fixe <chr>,
# date_inscription_iae <dttm>, prem_insc_univ_fr <dbl>,
# date_premiere_ins_ens_sup <dbl>, prem_insc_etab <dbl>, numins <chr>,
# compos <chr>, regime.y <dbl>, situpre <chr>, paripa <chr>, diplom <chr>,
# typrepa <chr>, dipder <chr>, niveau <chr>, etabli <chr>, acaeta <chr>,
# depeta <chr>, typ_dipl <chr>, sectdis <chr>, discipli <chr>, cycle <dbl>,
# degetu <chr>, curpar <chr>, nbach <dbl>, net <dbl>, effectif <dbl>,
# groupe <chr>, cursus_lmd <chr>, voie <dbl>, numed <chr>, flag_meef <dbl>,
# conv <chr>, specia <chr>, specib <chr>, etabli_diffusion <chr>, univ <chr>arrange(um18, desc(date_naiss))# A tibble: 70,800 x 72
decede annee_univ idetu civilite date_naiss code departement_pays
<chr> <dbl> <dbl> <chr> <dttm> <chr> <chr>
1 non 2018 2213486 M 2003-01-09 00:00:00 74 HAUTE SAVOIE
2 non 2018 2214054 M 2002-10-20 00:00:00 34 HERAULT
3 non 2018 916831 M 2002-04-29 00:00:00 69 RHONE
4 non 2018 2213274 M 2002-03-17 00:00:00 30 GARD
5 non 2018 2213678 M 2002-03-15 00:00:00 34 HERAULT
6 non 2018 916452 M 2002-02-13 00:00:00 322 CAMEROUN
7 non 2018 883861 M 2002-02-09 00:00:00 30 GARD
8 non 2018 2214045 M 2002-01-24 00:00:00 66 PYRENEES ORIENT…
9 non 2018 2213738 M 2002-01-20 00:00:00 34 HERAULT
10 non 2018 2213471 Mme 2002-01-09 00:00:00 51 MARNE
# … with 70,790 more rows, and 65 more variables: code_nationalite <dbl>,
# libelle_nationalite <chr>, bac <chr>, bac_regroup <chr>, annee_bac <dbl>,
# departement_bac <chr>, regime.x <chr>, bourse <chr>, echelon_bourse <chr>,
# pcs_parent <chr>, pcs_parent_autre <chr>, lic_tpd <chr>, composante <chr>,
# domaine_disciplinaire <chr>, mention <chr>, code_sise_diplome <dbl>,
# diplome <chr>, code_diplome <chr>, intitule1_sise <chr>, code_etape <chr>,
# lib_etape <chr>, intitule2_sise <chr>, version_de_diplome <chr>,
# inscription_premiere <chr>, nature_diplome <chr>, temoin_dip <chr>,
# cp_annuel <dbl>, pays_annuel <chr>, cp_fixe <dbl>, pays_fixe <chr>,
# date_inscription_iae <dttm>, prem_insc_univ_fr <dbl>,
# date_premiere_ins_ens_sup <dbl>, prem_insc_etab <dbl>, numins <chr>,
# compos <chr>, regime.y <dbl>, situpre <chr>, paripa <chr>, diplom <chr>,
# typrepa <chr>, dipder <chr>, niveau <chr>, etabli <chr>, acaeta <chr>,
# depeta <chr>, typ_dipl <chr>, sectdis <chr>, discipli <chr>, cycle <dbl>,
# degetu <chr>, curpar <chr>, nbach <dbl>, net <dbl>, effectif <dbl>,
# groupe <chr>, cursus_lmd <chr>, voie <dbl>, numed <chr>, flag_meef <dbl>,
# conv <chr>, specia <chr>, specib <chr>, etabli_diffusion <chr>, univ <chr>On peut évidemment aussi trier selon plusieurs colonnes successivement (pour départager les ex-aequos) en les entrant l’une après l’autre dans l’appel de la fonction :
arrange(um18, departement_pays, date_naiss)# A tibble: 70,800 x 72
decede annee_univ idetu civilite date_naiss code departement_pays
<chr> <dbl> <dbl> <chr> <dttm> <chr> <chr>
1 non 2018 914179 M 1983-04-30 00:00:00 212 AFGHANISTAN
2 non 2018 895315 Mme 1986-04-10 00:00:00 212 AFGHANISTAN
3 non 2018 913713 M 1992-03-02 00:00:00 212 AFGHANISTAN
4 non 2018 919274 Mme 1993-10-05 00:00:00 212 AFGHANISTAN
5 non 2018 892284 Mme 1994-01-15 00:00:00 212 AFGHANISTAN
6 non 2018 898947 M 1983-06-08 00:00:00 303 AFRIQUE DU SUD
7 non 2018 898385 Mme 1989-01-18 00:00:00 303 AFRIQUE DU SUD
8 non 2018 2223098 M 1992-03-13 00:00:00 303 AFRIQUE DU SUD
9 non 2018 901661 M 1994-07-29 00:00:00 303 AFRIQUE DU SUD
10 non 2018 889584 Mme 1995-02-07 00:00:00 303 AFRIQUE DU SUD
# … with 70,790 more rows, and 65 more variables: code_nationalite <dbl>,
# libelle_nationalite <chr>, bac <chr>, bac_regroup <chr>, annee_bac <dbl>,
# departement_bac <chr>, regime.x <chr>, bourse <chr>, echelon_bourse <chr>,
# pcs_parent <chr>, pcs_parent_autre <chr>, lic_tpd <chr>, composante <chr>,
# domaine_disciplinaire <chr>, mention <chr>, code_sise_diplome <dbl>,
# diplome <chr>, code_diplome <chr>, intitule1_sise <chr>, code_etape <chr>,
# lib_etape <chr>, intitule2_sise <chr>, version_de_diplome <chr>,
# inscription_premiere <chr>, nature_diplome <chr>, temoin_dip <chr>,
# cp_annuel <dbl>, pays_annuel <chr>, cp_fixe <dbl>, pays_fixe <chr>,
# date_inscription_iae <dttm>, prem_insc_univ_fr <dbl>,
# date_premiere_ins_ens_sup <dbl>, prem_insc_etab <dbl>, numins <chr>,
# compos <chr>, regime.y <dbl>, situpre <chr>, paripa <chr>, diplom <chr>,
# typrepa <chr>, dipder <chr>, niveau <chr>, etabli <chr>, acaeta <chr>,
# depeta <chr>, typ_dipl <chr>, sectdis <chr>, discipli <chr>, cycle <dbl>,
# degetu <chr>, curpar <chr>, nbach <dbl>, net <dbl>, effectif <dbl>,
# groupe <chr>, cursus_lmd <chr>, voie <dbl>, numed <chr>, flag_meef <dbl>,
# conv <chr>, specia <chr>, specib <chr>, etabli_diffusion <chr>, univ <chr>Attention : il n’est pas recommandé de sauvegarder des données après les avoir triées… L’ordre n’a pas d’importance en soi, et quand il est nécessaire, doit être fait à la volée.
4.4.3 Sélectionner des variables : select()
Encore un verbe plutôt intuitif : select() permet de ne conserver que les
variables spécifiées. Dans sa forme la plus simple, on renseigne simplement les
colonnes d’intérêt l’une après l’autre :
select(um18, diplome, code_diplome)# A tibble: 70,800 x 2
diplome code_diplome
<chr> <chr>
1 Licence en Droit DLD
2 Statut Auditeur UMAUD
3 DUT Mesures Physiques MPD
4 Doct. Chim et Physico-Chi VDRCPC
5 Doct. Biologie Santé VDRBSA
6 Doct. Sc Agronomiques VDRSAG
7 Doct. Chim et Physico-Chi VDRCPC
8 Doct. Biologie Santé VDRBSA
9 Doct. Evol System Infecti VDRESI
10 Doct. Sc Aliments Nutriti VDRSAN
# … with 70,790 more rowsselect() permet en outre une syntaxe assez élaborée pour plus de flexibilité,
par exemple avec l’utilisation de ! pour avoir le sous-ensemble inverse de
colonnes. On peut enlever l’ID étudiant ainsi :
select(um18, !idetu)# A tibble: 70,800 x 71
decede annee_univ civilite date_naiss code departement_pays
<chr> <dbl> <chr> <dttm> <chr> <chr>
1 non 2018 Mme 2000-10-05 00:00:00 84 VAUCLUSE
2 non 2018 M 1997-06-16 00:00:00 6 ALPES MARITIMES
3 non 2018 M 2000-04-13 00:00:00 84 VAUCLUSE
4 non 2018 Mme 1993-10-08 00:00:00 205 LIBAN
5 non 2018 Mme 1994-10-02 00:00:00 352 ALGERIE
6 non 2018 M 1992-03-27 00:00:00 127 ITALIE
7 non 2018 Mme 1995-10-06 00:00:00 205 LIBAN
8 non 2018 M 1995-05-05 00:00:00 134 ESPAGNE
9 non 2018 Mme 1990-01-08 00:00:00 331 BURKINA FASO
10 non 2018 M 1988-05-01 00:00:00 352 ALGERIE
# … with 70,790 more rows, and 65 more variables: code_nationalite <dbl>,
# libelle_nationalite <chr>, bac <chr>, bac_regroup <chr>, annee_bac <dbl>,
# departement_bac <chr>, regime.x <chr>, bourse <chr>, echelon_bourse <chr>,
# pcs_parent <chr>, pcs_parent_autre <chr>, lic_tpd <chr>, composante <chr>,
# domaine_disciplinaire <chr>, mention <chr>, code_sise_diplome <dbl>,
# diplome <chr>, code_diplome <chr>, intitule1_sise <chr>, code_etape <chr>,
# lib_etape <chr>, intitule2_sise <chr>, version_de_diplome <chr>,
# inscription_premiere <chr>, nature_diplome <chr>, temoin_dip <chr>,
# cp_annuel <dbl>, pays_annuel <chr>, cp_fixe <dbl>, pays_fixe <chr>,
# date_inscription_iae <dttm>, prem_insc_univ_fr <dbl>,
# date_premiere_ins_ens_sup <dbl>, prem_insc_etab <dbl>, numins <chr>,
# compos <chr>, regime.y <dbl>, situpre <chr>, paripa <chr>, diplom <chr>,
# typrepa <chr>, dipder <chr>, niveau <chr>, etabli <chr>, acaeta <chr>,
# depeta <chr>, typ_dipl <chr>, sectdis <chr>, discipli <chr>, cycle <dbl>,
# degetu <chr>, curpar <chr>, nbach <dbl>, net <dbl>, effectif <dbl>,
# groupe <chr>, cursus_lmd <chr>, voie <dbl>, numed <chr>, flag_meef <dbl>,
# conv <chr>, specia <chr>, specib <chr>, etabli_diffusion <chr>, univ <chr>Ou bien sélectionner une suite de colonne en utilisant l’opérateur : ; par
exemple toutes les colonnes entre "bac" et "département_bac" :
select(um18, bac:departement_bac)# A tibble: 70,800 x 4
bac bac_regroup annee_bac departement_bac
<chr> <chr> <dbl> <chr>
1 S-Sciences Bac général scientifique 2018 84
2 L-littérat Bac général littéraire 2018 34
3 S-Sciences Bac général scientifique 2018 30
4 0031-étran Autres bacs ou équivalence 2011 99
5 0031-étran Autres bacs ou équivalence 2013 99
6 0031-étran Autres bacs ou équivalence 2013 99
7 0031-étran Autres bacs ou équivalence 2013 99
8 0031-étran Autres bacs ou équivalence 2013 99
9 0031-étran Autres bacs ou équivalence 2009 99
10 0031-étran Autres bacs ou équivalence 2005 99
# … with 70,790 more rowsselect(um18, !(bac:departement_bac))# A tibble: 70,800 x 68
decede annee_univ idetu civilite date_naiss code departement_pays
<chr> <dbl> <dbl> <chr> <dttm> <chr> <chr>
1 non 2018 1035789 Mme 2000-10-05 00:00:00 84 VAUCLUSE
2 non 2018 2211839 M 1997-06-16 00:00:00 6 ALPES MARITIMES
3 non 2018 2211840 M 2000-04-13 00:00:00 84 VAUCLUSE
4 non 2018 921768 Mme 1993-10-08 00:00:00 205 LIBAN
5 non 2018 921685 Mme 1994-10-02 00:00:00 352 ALGERIE
6 non 2018 2211841 M 1992-03-27 00:00:00 127 ITALIE
7 non 2018 921909 Mme 1995-10-06 00:00:00 205 LIBAN
8 non 2018 921827 M 1995-05-05 00:00:00 134 ESPAGNE
9 non 2018 2211842 Mme 1990-01-08 00:00:00 331 BURKINA FASO
10 non 2018 921775 M 1988-05-01 00:00:00 352 ALGERIE
# … with 70,790 more rows, and 61 more variables: code_nationalite <dbl>,
# libelle_nationalite <chr>, regime.x <chr>, bourse <chr>,
# echelon_bourse <chr>, pcs_parent <chr>, pcs_parent_autre <chr>,
# lic_tpd <chr>, composante <chr>, domaine_disciplinaire <chr>,
# mention <chr>, code_sise_diplome <dbl>, diplome <chr>, code_diplome <chr>,
# intitule1_sise <chr>, code_etape <chr>, lib_etape <chr>,
# intitule2_sise <chr>, version_de_diplome <chr>, inscription_premiere <chr>,
# nature_diplome <chr>, temoin_dip <chr>, cp_annuel <dbl>, pays_annuel <chr>,
# cp_fixe <dbl>, pays_fixe <chr>, date_inscription_iae <dttm>,
# prem_insc_univ_fr <dbl>, date_premiere_ins_ens_sup <dbl>,
# prem_insc_etab <dbl>, numins <chr>, compos <chr>, regime.y <dbl>,
# situpre <chr>, paripa <chr>, diplom <chr>, typrepa <chr>, dipder <chr>,
# niveau <chr>, etabli <chr>, acaeta <chr>, depeta <chr>, typ_dipl <chr>,
# sectdis <chr>, discipli <chr>, cycle <dbl>, degetu <chr>, curpar <chr>,
# nbach <dbl>, net <dbl>, effectif <dbl>, groupe <chr>, cursus_lmd <chr>,
# voie <dbl>, numed <chr>, flag_meef <dbl>, conv <chr>, specia <chr>,
# specib <chr>, etabli_diffusion <chr>, univ <chr>Ou encore toutes les colonnes dont le nom contient le terme "bac" :
select(um18, contains("bac"))# A tibble: 70,800 x 5
bac bac_regroup annee_bac departement_bac nbach
<chr> <chr> <dbl> <chr> <dbl>
1 S-Sciences Bac général scientifique 2018 84 1
2 L-littérat Bac général littéraire 2018 34 NA
3 S-Sciences Bac général scientifique 2018 30 NA
4 0031-étran Autres bacs ou équivalence 2011 99 0
5 0031-étran Autres bacs ou équivalence 2013 99 0
6 0031-étran Autres bacs ou équivalence 2013 99 NA
7 0031-étran Autres bacs ou équivalence 2013 99 0
8 0031-étran Autres bacs ou équivalence 2013 99 0
9 0031-étran Autres bacs ou équivalence 2009 99 NA
10 0031-étran Autres bacs ou équivalence 2005 99 0
# … with 70,790 more rows4.4.4 Créer et modifier des variables : mutate()
Sans aucun doute l’un des verbes les plus régulièrement utilisés, mutate()
permet de créer de nouvelles variables à partir de celles déjà existantes, à
l’aide de n’importe quelle opération statistique autorisée par R. Ici, on enlève
2000 à l’année de première inscription pour obtenir l’année simplifiée :
mutate(um18, prem_insc_univ_fr_2000 = prem_insc_univ_fr - 2000)# A tibble: 70,800 x 73
decede annee_univ idetu civilite date_naiss code departement_pays
<chr> <dbl> <dbl> <chr> <dttm> <chr> <chr>
1 non 2018 1035789 Mme 2000-10-05 00:00:00 84 VAUCLUSE
2 non 2018 2211839 M 1997-06-16 00:00:00 6 ALPES MARITIMES
3 non 2018 2211840 M 2000-04-13 00:00:00 84 VAUCLUSE
4 non 2018 921768 Mme 1993-10-08 00:00:00 205 LIBAN
5 non 2018 921685 Mme 1994-10-02 00:00:00 352 ALGERIE
6 non 2018 2211841 M 1992-03-27 00:00:00 127 ITALIE
7 non 2018 921909 Mme 1995-10-06 00:00:00 205 LIBAN
8 non 2018 921827 M 1995-05-05 00:00:00 134 ESPAGNE
9 non 2018 2211842 Mme 1990-01-08 00:00:00 331 BURKINA FASO
10 non 2018 921775 M 1988-05-01 00:00:00 352 ALGERIE
# … with 70,790 more rows, and 66 more variables: code_nationalite <dbl>,
# libelle_nationalite <chr>, bac <chr>, bac_regroup <chr>, annee_bac <dbl>,
# departement_bac <chr>, regime.x <chr>, bourse <chr>, echelon_bourse <chr>,
# pcs_parent <chr>, pcs_parent_autre <chr>, lic_tpd <chr>, composante <chr>,
# domaine_disciplinaire <chr>, mention <chr>, code_sise_diplome <dbl>,
# diplome <chr>, code_diplome <chr>, intitule1_sise <chr>, code_etape <chr>,
# lib_etape <chr>, intitule2_sise <chr>, version_de_diplome <chr>,
# inscription_premiere <chr>, nature_diplome <chr>, temoin_dip <chr>,
# cp_annuel <dbl>, pays_annuel <chr>, cp_fixe <dbl>, pays_fixe <chr>,
# date_inscription_iae <dttm>, prem_insc_univ_fr <dbl>,
# date_premiere_ins_ens_sup <dbl>, prem_insc_etab <dbl>, numins <chr>,
# compos <chr>, regime.y <dbl>, situpre <chr>, paripa <chr>, diplom <chr>,
# typrepa <chr>, dipder <chr>, niveau <chr>, etabli <chr>, acaeta <chr>,
# depeta <chr>, typ_dipl <chr>, sectdis <chr>, discipli <chr>, cycle <dbl>,
# degetu <chr>, curpar <chr>, nbach <dbl>, net <dbl>, effectif <dbl>,
# groupe <chr>, cursus_lmd <chr>, voie <dbl>, numed <chr>, flag_meef <dbl>,
# conv <chr>, specia <chr>, specib <chr>, etabli_diffusion <chr>, univ <chr>,
# prem_insc_univ_fr_2000 <dbl>On peut s’en servir aussi pour recoder une variable, à l’aide de la fonction
recode(). Ici, la variable "decede" est transformée en variable logique
"vivant" (TRUE/FALSE) :
mutate(um18, vivant = recode(decede, "non" = TRUE, "oui" = FALSE))# A tibble: 70,800 x 73
decede annee_univ idetu civilite date_naiss code departement_pays
<chr> <dbl> <dbl> <chr> <dttm> <chr> <chr>
1 non 2018 1035789 Mme 2000-10-05 00:00:00 84 VAUCLUSE
2 non 2018 2211839 M 1997-06-16 00:00:00 6 ALPES MARITIMES
3 non 2018 2211840 M 2000-04-13 00:00:00 84 VAUCLUSE
4 non 2018 921768 Mme 1993-10-08 00:00:00 205 LIBAN
5 non 2018 921685 Mme 1994-10-02 00:00:00 352 ALGERIE
6 non 2018 2211841 M 1992-03-27 00:00:00 127 ITALIE
7 non 2018 921909 Mme 1995-10-06 00:00:00 205 LIBAN
8 non 2018 921827 M 1995-05-05 00:00:00 134 ESPAGNE
9 non 2018 2211842 Mme 1990-01-08 00:00:00 331 BURKINA FASO
10 non 2018 921775 M 1988-05-01 00:00:00 352 ALGERIE
# … with 70,790 more rows, and 66 more variables: code_nationalite <dbl>,
# libelle_nationalite <chr>, bac <chr>, bac_regroup <chr>, annee_bac <dbl>,
# departement_bac <chr>, regime.x <chr>, bourse <chr>, echelon_bourse <chr>,
# pcs_parent <chr>, pcs_parent_autre <chr>, lic_tpd <chr>, composante <chr>,
# domaine_disciplinaire <chr>, mention <chr>, code_sise_diplome <dbl>,
# diplome <chr>, code_diplome <chr>, intitule1_sise <chr>, code_etape <chr>,
# lib_etape <chr>, intitule2_sise <chr>, version_de_diplome <chr>,
# inscription_premiere <chr>, nature_diplome <chr>, temoin_dip <chr>,
# cp_annuel <dbl>, pays_annuel <chr>, cp_fixe <dbl>, pays_fixe <chr>,
# date_inscription_iae <dttm>, prem_insc_univ_fr <dbl>,
# date_premiere_ins_ens_sup <dbl>, prem_insc_etab <dbl>, numins <chr>,
# compos <chr>, regime.y <dbl>, situpre <chr>, paripa <chr>, diplom <chr>,
# typrepa <chr>, dipder <chr>, niveau <chr>, etabli <chr>, acaeta <chr>,
# depeta <chr>, typ_dipl <chr>, sectdis <chr>, discipli <chr>, cycle <dbl>,
# degetu <chr>, curpar <chr>, nbach <dbl>, net <dbl>, effectif <dbl>,
# groupe <chr>, cursus_lmd <chr>, voie <dbl>, numed <chr>, flag_meef <dbl>,
# conv <chr>, specia <chr>, specib <chr>, etabli_diffusion <chr>, univ <chr>,
# vivant <lgl>Note : Si l’on ne voulait conserver que les variables nouvellement créées, on
utiliserait alors transmute() en lieu et place de mutate().
4.4.5 Nom d’une pipe !
Tout ceci est bien intéressant, mais parfois peu lisible, et on voit bien
comment une suite d’opérations deviendrait tout à fait infernale en terme de
code. Pour résoudre ce problème, l’opérateur tube, ou pipe en anglais, a été
implémenté sous R (%>%, raccourci Ctrl+Shift+M). Cet opérateur permet tout
simplement d’envoyer à la séquence suivante le résultat précédent. Celui-ci est
implicitement utilisé, mais on peut avoir besoin de le rendre explicite à l’aide
du point (.). Un court exemple l’illustre bien :
4 %>% sqrt()[1] 24 %>% sqrt() %>% seq(from = 10, to = ., by = -2)[1] 10 8 6 4 2C’est avec l’utilisation des fonctions de manipulation de données que cet
opérateur prend tout son sens. Dans l’exemple suivant, on envoie le jeu de
données um18 à la fonction mutate(), avant d’envoyer le tableau résultat à
la fonction select() et de ne visualiser que les deux variables d’intérêt.
Beaucoup plus lisible !
um18 %>%
mutate(vivant = recode(decede, "non" = TRUE, "oui" = FALSE)) %>%
select(decede, vivant)# A tibble: 70,800 x 2
decede vivant
<chr> <lgl>
1 non TRUE
2 non TRUE
3 non TRUE
4 non TRUE
5 non TRUE
6 non TRUE
7 non TRUE
8 non TRUE
9 non TRUE
10 non TRUE
# … with 70,790 more rowsOn peut ainsi « empiler » les opérations successives, de manière très intuitive.
Cerise sur le gâteau, on peut en bout de ligne envoyer le résultat des
opérations à ggplot2 pour en tirer un graphique ! Le graphique sur l’âge des
étudiants, présenté en exemple du module de dataviz, a été créé ainsi (à
l’exception du thème sombre) :
library("ggplot2")
um18 %>%
mutate(age = (as.POSIXct("2018-09-01") - date_naiss)/365.24) %>%
ggplot(aes(x = bac_regroup, y = age, color = bac_regroup)) +
geom_jitter(alpha = 0.05) +
geom_boxplot(alpha = 0, color = grey(0.2), size = 1) +
labs(title = "Quel est l'âge de nos étudiants, selon la filière du baccalauréat ?",
subtitle = "(données pour les inscriptions à l'Université de Montpellier 2018–2019)",
x = "Type de baccalauréat",
y = "Âge (tronqué à 55)") +
coord_cartesian(ylim = c(18, 55)) +
theme_classic() +
theme(legend.position = "none",
axis.text.x = element_text(angle = -45, vjust = 0.1, hjust = 0.1))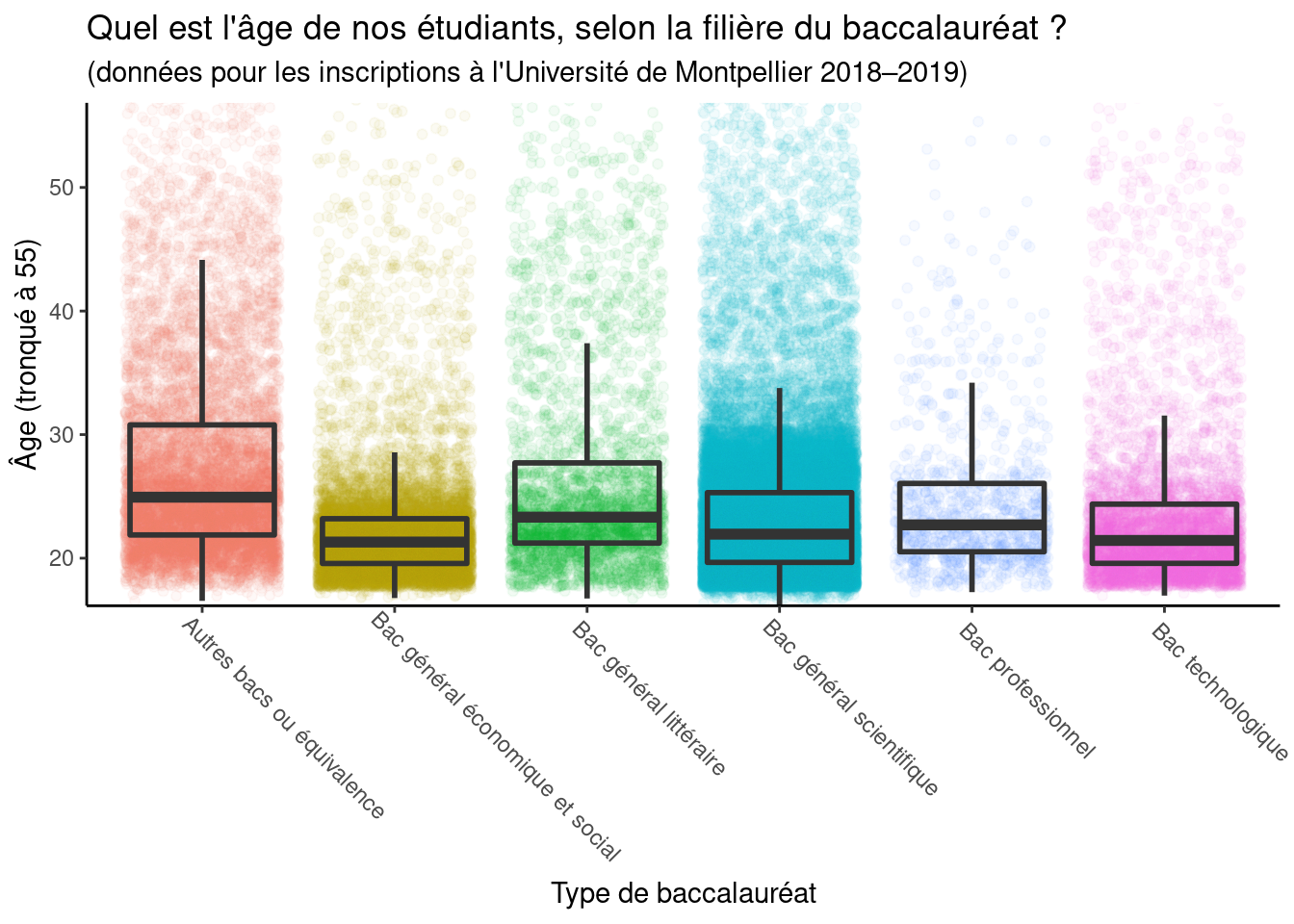
Exercice 1 : Dans cet exercice, on va simplement reprendre les exemples ci-dessus en utilisant cette fois les tubes. Vous avez ensuite carte blanche pour les combiner et ainsi multiplier les opérations en un clin d’œil.
4.4.6 Petit apparté sur les chaînes de caractères
La manipulation des chaînes de caractères est tout à fait possible sous R : le
package stringr notamment propose tout un tas de fonctions pour détecter,
modifier, remplacer, etc. des chaînes de caractères. À ce sujet, on peut aller
très loin avec les expressions régulières, qui permettent de travailler très
finement sur des chaînes de caractères, au prix d’un code largement abscons.
Afin de faciliter la suite des opérations, nous allons créer ici trois nouvelles
variables abrégées : $bac_abr, $dom_abr et $men_abr qui seront le type de
bac, le domaine disciplinaire et la mention abrégés, respectivement.
Sans rentrer dans les détails, voici comment obtenir ces variables :
um18$bac_abr <- recode(um18$bac_regroup,
"Bac général scientifique" = "S",
"Bac général littéraire" = "L",
"Autres bacs ou équivalence" = "o",
"Bac général économique et social" = "ES",
"Bac professionnel" = "Pro",
"Bac technologique" = "T")
table(um18$bac_regroup)
Autres bacs ou équivalence Bac général économique et social
9207 11782
Bac général littéraire Bac général scientifique
3553 39465
Bac professionnel Bac technologique
1037 5756 table(um18$bac_abr)
ES L o Pro S T
11782 3553 9207 1037 39465 5756 um18$dom_abr <- um18$domaine_disciplinaire %>%
## Enlève les mots de 2 lettres ou moins :
stringr::str_replace_all("\\b\\w{1,2}\\b", "") %>%
## Abrège en ne gardant que l'initiale de chaque mot :
abbreviate(minlength = 1, named = FALSE)
table(um18$domaine_disciplinaire)
ARTS, LETTRES, LANGUES DROIT-SCIENCE POLITIQUE
79 534
DROIT, ECONOMIE, GESTION SCIENCES ET TECHNOLOGIES
12612 3382
SCIENCES HUMAINES ET SOCIALES SCIENCES, TECHNOLOGIES, SANTE
294 19802 table(um18$dom_abr)
ALL DEG DP SHS ST STS
79 12612 534 294 3382 19802 um18$men_abr <- um18$mention %>%
## Remplace ' ; et : par un espace :
stringr::str_replace_all("'|,|:", " ") %>%
## Enlève les mots de 3 lettres ou moins :
stringr::str_replace_all("\\b\\w{1,3}\\b", "") %>%
## Enlève tous les espaces superflus :
stringr::str_squish() %>%
## Passe toutes les initiales en majuscules :
stringr::str_to_title() %>%
## Abrège en gardant au maximum 20 lettres :
abbreviate(minlength = 20, named = FALSE)
um18 %>%
select(mention, men_abr) %>%
distinct(mention, men_abr) %>%
slice_head(n = 10)# A tibble: 10 x 2
mention men_abr
<chr> <chr>
1 Droit Droit
2 <NA> <NA>
3 Science politique Science Politique
4 Qualité, Hygiène, Sécurité, Santé, Environnement QltHygnScrtSntEnvrnn
5 Finances publiques Finances Publiques
6 Droit privé Droit Privé
7 Risques et environnement RisquesEnvironnement
8 Activités juridiques : assistant juridique ActvtsJrdqsAssstntJr
9 Droit pénal et sciences criminelles DroitPnlScncsCrmnlls
10 Droit de l'entreprise Droit Entreprise 4.5 Synthétiser des données
4.5.1 Grouper des lignes : group_by()
Ce verbe est bien mystérieux : il semble ne rien faire de spécial par lui-même… La seule différence visible est qu’un facteur de regroupement est indiqué :
group_by(um18, domaine_disciplinaire)# A tibble: 70,800 x 75
# Groups: domaine_disciplinaire [7]
decede annee_univ idetu civilite date_naiss code departement_pays
<chr> <dbl> <dbl> <chr> <dttm> <chr> <chr>
1 non 2018 1035789 Mme 2000-10-05 00:00:00 84 VAUCLUSE
2 non 2018 2211839 M 1997-06-16 00:00:00 6 ALPES MARITIMES
3 non 2018 2211840 M 2000-04-13 00:00:00 84 VAUCLUSE
4 non 2018 921768 Mme 1993-10-08 00:00:00 205 LIBAN
5 non 2018 921685 Mme 1994-10-02 00:00:00 352 ALGERIE
6 non 2018 2211841 M 1992-03-27 00:00:00 127 ITALIE
7 non 2018 921909 Mme 1995-10-06 00:00:00 205 LIBAN
8 non 2018 921827 M 1995-05-05 00:00:00 134 ESPAGNE
9 non 2018 2211842 Mme 1990-01-08 00:00:00 331 BURKINA FASO
10 non 2018 921775 M 1988-05-01 00:00:00 352 ALGERIE
# … with 70,790 more rows, and 68 more variables: code_nationalite <dbl>,
# libelle_nationalite <chr>, bac <chr>, bac_regroup <chr>, annee_bac <dbl>,
# departement_bac <chr>, regime.x <chr>, bourse <chr>, echelon_bourse <chr>,
# pcs_parent <chr>, pcs_parent_autre <chr>, lic_tpd <chr>, composante <chr>,
# domaine_disciplinaire <chr>, mention <chr>, code_sise_diplome <dbl>,
# diplome <chr>, code_diplome <chr>, intitule1_sise <chr>, code_etape <chr>,
# lib_etape <chr>, intitule2_sise <chr>, version_de_diplome <chr>,
# inscription_premiere <chr>, nature_diplome <chr>, temoin_dip <chr>,
# cp_annuel <dbl>, pays_annuel <chr>, cp_fixe <dbl>, pays_fixe <chr>,
# date_inscription_iae <dttm>, prem_insc_univ_fr <dbl>,
# date_premiere_ins_ens_sup <dbl>, prem_insc_etab <dbl>, numins <chr>,
# compos <chr>, regime.y <dbl>, situpre <chr>, paripa <chr>, diplom <chr>,
# typrepa <chr>, dipder <chr>, niveau <chr>, etabli <chr>, acaeta <chr>,
# depeta <chr>, typ_dipl <chr>, sectdis <chr>, discipli <chr>, cycle <dbl>,
# degetu <chr>, curpar <chr>, nbach <dbl>, net <dbl>, effectif <dbl>,
# groupe <chr>, cursus_lmd <chr>, voie <dbl>, numed <chr>, flag_meef <dbl>,
# conv <chr>, specia <chr>, specib <chr>, etabli_diffusion <chr>, univ <chr>,
# bac_abr <chr>, dom_abr <chr>, men_abr <chr>Mais attention, il affecte bien d’autres fonctions ! Son rôle consiste justement à indiquer un possible regroupement de données qui sera utiliser pour les opérations ultérieures. Dans l’exemple ci-dessus, les opérations ne seront plus effectuées sur le tableau global, mais par domaine disciplinaire.
4.5.2 Calculer des résumés des données : summarise()
summarise() est le verbe parfait pour synthétiser l’information. Il permet de
produire un tableau résumé (généralement avec peu de lignes) comportant les
informations demandées, comme par exemple le nombre d’individus, ou bien des
statistiques sur les ensembles :
summarise(um18,
n = n(),
date_naiss_min = min(date_naiss),
date_naiss_moy = mean(date_naiss),
date_naiss_max = max(date_naiss)
)# A tibble: 1 x 4
n date_naiss_min date_naiss_moy date_naiss_max
<int> <dttm> <dttm> <dttm>
1 70800 1936-08-25 00:00:00 1994-08-30 23:19:14 2003-01-09 00:00:00Toute la beauté du verbe devient apparente lorsque l’on définit des groupes au préalables. On peut par exemple calculer les mêmes statistiques que précédemment, mais cette fois par domaine disciplinaire (et en enlevant les valeurs manquantes au passage pour la bonne cause) :
um18 %>%
filter(!is.na(domaine_disciplinaire)) %>%
group_by(domaine_disciplinaire) %>%
summarise(
n = n(),
date_naiss_min = min(date_naiss),
date_naiss_moy = mean(date_naiss),
date_naiss_max = max(date_naiss)
)# A tibble: 6 x 5
domaine_disciplinaire n date_naiss_min date_naiss_moy
<chr> <int> <dttm> <dttm>
1 ARTS, LETTRES, LANGUES 79 1961-01-01 00:00:00 1989-06-29 03:56:57
2 DROIT-SCIENCE POLITIQUE 534 1959-03-22 00:00:00 1996-12-11 15:54:36
3 DROIT, ECONOMIE, GESTION 12612 1947-11-18 00:00:00 1996-07-10 08:29:00
4 SCIENCES ET TECHNOLOGIES 3382 1970-12-07 00:00:00 1999-05-04 04:21:25
5 SCIENCES HUMAINES ET SOCIALES 294 1955-11-01 00:00:00 1984-09-15 05:47:45
6 SCIENCES, TECHNOLOGIES, SANTE 19802 1950-09-08 00:00:00 1995-10-15 01:59:33
# … with 1 more variable: date_naiss_max <dttm>4.5.3 Compter les observations : count()
Nous venons de voir que l’on pouvait obtenir le nombre d’individus avec la fonction n(). Celle-ci ne fonctionne toutefois qu’à l’intérieur des fonctions summarise() ou mutate(), il nous faut donc autre chose pour pouvoir compter tout ce que l’on veut : le verbe count() est là pour ça.
count(um18, departement_pays)# A tibble: 265 x 2
departement_pays n
<chr> <int>
1 AFGHANISTAN 5
2 AFRIQUE DU SUD 9
3 AIN 190
4 AISNE 194
5 ALBANIE 42
6 ALGERIE 1641
7 ALLEMAGNE 400
8 ALLIER 135
9 ALPES DE HAUTE PROVENCE 112
10 ALPES MARITIMES 735
# … with 255 more rowsMaintenant que l’on a le tube à portée de mains, on peut facilement faire un peu
de ménage dans cette commande en rangeant les départements/pays par ordre
décroissant (arrange()) et en ne conservant que les 5 premières lignes
(slice_head()) :
um18 %>%
count(departement_pays, name = "netu") %>%
arrange(desc(netu)) %>%
slice_head(n = 5)# A tibble: 5 x 2
departement_pays netu
<chr> <int>
1 HERAULT 15156
2 GARD 5604
3 PYRENEES ORIENTALES 2237
4 VAUCLUSE 2090
5 BOUCHES DU RHONE 2020La fonction slice_max() nous permet de le faire en une seule opération :
um18 %>%
count(departement_pays, name = "netu") %>%
slice_max(netu, n = 5)# A tibble: 5 x 2
departement_pays netu
<chr> <int>
1 HERAULT 15156
2 GARD 5604
3 PYRENEES ORIENTALES 2237
4 VAUCLUSE 2090
5 BOUCHES DU RHONE 2020Finalement, on peut aller un peu plus loin et grouper la sortie de count()
avant de faire d’autres opérations dessus — ici, on calcule les proportions par
groupe (et l’on voit que l’on peut utiliser plusieurs critères de regroupement
pour le comptage par count()) :
um18 %>%
filter(!is.na(domaine_disciplinaire)) %>%
count(domaine_disciplinaire, inscription_premiere, bac_regroup) %>%
group_by(domaine_disciplinaire, inscription_premiere) %>%
mutate(prop = n / sum(n))# A tibble: 59 x 5
# Groups: domaine_disciplinaire, inscription_premiere [11]
domaine_disciplinaire inscription_premi… bac_regroup n prop
<chr> <chr> <chr> <int> <dbl>
1 ARTS, LETTRES, LANGUES oui Autres bacs ou équi… 9 0.114
2 ARTS, LETTRES, LANGUES oui Bac général économi… 16 0.203
3 ARTS, LETTRES, LANGUES oui Bac général littéra… 37 0.468
4 ARTS, LETTRES, LANGUES oui Bac général scienti… 10 0.127
5 ARTS, LETTRES, LANGUES oui Bac professionnel 2 0.0253
6 ARTS, LETTRES, LANGUES oui Bac technologique 5 0.0633
7 DROIT-SCIENCE POLITIQUE non Autres bacs ou équi… 8 0.0179
8 DROIT-SCIENCE POLITIQUE non Bac général économi… 227 0.507
9 DROIT-SCIENCE POLITIQUE non Bac général littéra… 63 0.141
10 DROIT-SCIENCE POLITIQUE non Bac général scienti… 137 0.306
11 DROIT-SCIENCE POLITIQUE non Bac professionnel 5 0.0112
12 DROIT-SCIENCE POLITIQUE non Bac technologique 8 0.0179
13 DROIT-SCIENCE POLITIQUE oui Autres bacs ou équi… 5 0.0581
14 DROIT-SCIENCE POLITIQUE oui Bac général économi… 39 0.453
15 DROIT-SCIENCE POLITIQUE oui Bac général littéra… 11 0.128
16 DROIT-SCIENCE POLITIQUE oui Bac général scienti… 30 0.349
17 DROIT-SCIENCE POLITIQUE oui Bac technologique 1 0.0116
18 DROIT, ECONOMIE, GESTI… non Autres bacs ou équi… 56 0.225
19 DROIT, ECONOMIE, GESTI… non Bac général économi… 40 0.161
20 DROIT, ECONOMIE, GESTI… non Bac général littéra… 7 0.0281
21 DROIT, ECONOMIE, GESTI… non Bac général scienti… 130 0.522
22 DROIT, ECONOMIE, GESTI… non Bac professionnel 2 0.00803
23 DROIT, ECONOMIE, GESTI… non Bac technologique 14 0.0562
24 DROIT, ECONOMIE, GESTI… oui Autres bacs ou équi… 1774 0.143
25 DROIT, ECONOMIE, GESTI… oui Bac général économi… 5120 0.414
26 DROIT, ECONOMIE, GESTI… oui Bac général littéra… 1011 0.0818
27 DROIT, ECONOMIE, GESTI… oui Bac général scienti… 2997 0.242
28 DROIT, ECONOMIE, GESTI… oui Bac professionnel 292 0.0236
29 DROIT, ECONOMIE, GESTI… oui Bac technologique 1169 0.0946
30 SCIENCES ET TECHNOLOGI… non Autres bacs ou équi… 61 0.488
31 SCIENCES ET TECHNOLOGI… non Bac général économi… 6 0.048
32 SCIENCES ET TECHNOLOGI… non Bac général littéra… 3 0.024
33 SCIENCES ET TECHNOLOGI… non Bac général scienti… 33 0.264
34 SCIENCES ET TECHNOLOGI… non Bac technologique 22 0.176
35 SCIENCES ET TECHNOLOGI… oui Autres bacs ou équi… 145 0.0445
36 SCIENCES ET TECHNOLOGI… oui Bac général économi… 411 0.126
37 SCIENCES ET TECHNOLOGI… oui Bac général littéra… 16 0.00491
38 SCIENCES ET TECHNOLOGI… oui Bac général scienti… 1987 0.610
39 SCIENCES ET TECHNOLOGI… oui Bac professionnel 5 0.00154
40 SCIENCES ET TECHNOLOGI… oui Bac technologique 693 0.213
41 SCIENCES HUMAINES ET S… non Autres bacs ou équi… 1 1
42 SCIENCES HUMAINES ET S… oui Autres bacs ou équi… 56 0.191
43 SCIENCES HUMAINES ET S… oui Bac général économi… 76 0.259
44 SCIENCES HUMAINES ET S… oui Bac général littéra… 62 0.212
45 SCIENCES HUMAINES ET S… oui Bac général scienti… 49 0.167
46 SCIENCES HUMAINES ET S… oui Bac professionnel 8 0.0273
47 SCIENCES HUMAINES ET S… oui Bac technologique 42 0.143
48 SCIENCES, TECHNOLOGIES… non Autres bacs ou équi… 150 0.0575
49 SCIENCES, TECHNOLOGIES… non Bac général économi… 552 0.212
50 SCIENCES, TECHNOLOGIES… non Bac général littéra… 433 0.166
51 SCIENCES, TECHNOLOGIES… non Bac général scienti… 1205 0.462
52 SCIENCES, TECHNOLOGIES… non Bac professionnel 35 0.0134
53 SCIENCES, TECHNOLOGIES… non Bac technologique 233 0.0893
54 SCIENCES, TECHNOLOGIES… oui Autres bacs ou équi… 1984 0.115
55 SCIENCES, TECHNOLOGIES… oui Bac général économi… 1774 0.103
56 SCIENCES, TECHNOLOGIES… oui Bac général littéra… 637 0.0370
57 SCIENCES, TECHNOLOGIES… oui Bac général scienti… 10900 0.634
58 SCIENCES, TECHNOLOGIES… oui Bac professionnel 289 0.0168
59 SCIENCES, TECHNOLOGIES… oui Bac technologique 1610 0.0936 Exercice 2 : Dans cet exercice, on va recalculer les proportions du diagramme en barre du dernier module où l’on croisait les trois variables qualitatives « Domaine disciplinaire », « Inscription principale » et « Type de bac ». L’objectif est de se rapprocher du résultat suivant :
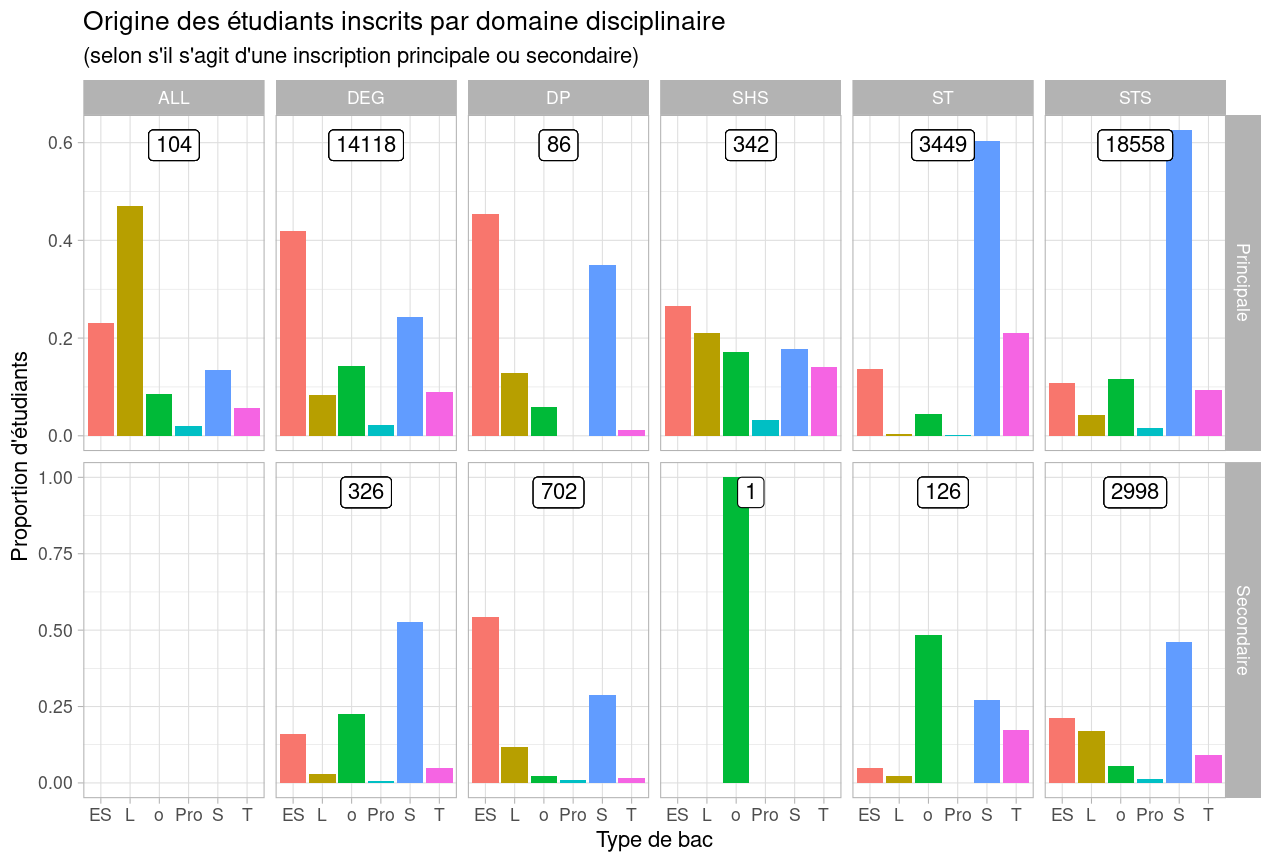
Avertissement : Ce n’est pas simple du tout ! Quelques indications :
- On n’oublie pas d’enlever les valeurs manquantes ;
-
On pourra recoder
bac_regroup,domaine_disciplinaireetinscription_premierepour y voir un peu plus clair ; -
N’oubliez pas que les opérations de comptage (
count()) et de regroupement (group_by) peuvent recevoir plusieurs variables indicatives ; -
La géométrie
geom_bar()vue précédemment peut aussi ne pas compter les individus et simplement reporter les valeurs fournies, à l’aide du paramètrestat = “identity”; -
Finalement, pour les plus aventureux, on pourra rajouter le nombre d’individus par groupe à l’aide de la géométrie
geom_label().
Question subsidiaire : Est-ce que cette nouvelle version change l’interprétation de ces données ?